

Performance benchmarking is one of the most misused tools in a developer's kit. Engineers run a quick timing loop, see a number drop, declare victory, and ship code that performs worse in production than the version it replaced. The root problem is not laziness but a fundamental misunderstanding of what benchmarks actually measure and what they do not. Misleading results compound into misguided optimizations, wasted sprints, and production regressions that nobody can explain. The gap between running a benchmark and running a correct benchmark is where most engineering teams silently lose credibility with their own data.
Most benchmark testing failures trace back to a single issue: developers measure something, but not the thing they think they are measuring. The environment, the toolchain, the runtime, and even the operating system scheduler all inject noise into results. Without controlling for these variables, a benchmark is just a random number generator wearing a lab coat.
One of the most persistent mistakes is treating profiling and benchmarking as interchangeable. They serve different purposes entirely. A profiler tells you where time is spent inside your code. A benchmark tells you how fast a specific operation runs under controlled conditions. Conflating the two leads to optimizing the wrong thing or measuring the wrong metric. As one practical handbook on the distinction puts it, profiling is diagnostic while benchmarking is evaluative.
Profiling: identifies hotspots, call-graph bottlenecks, and memory allocation patterns in running code
Benchmarking: quantifies the throughput or latency of a specific function, endpoint, or workflow under repeatable conditions
When to profile: when you do not yet know what is slow and need to narrow the search
When to benchmark: when you know what to measure and need a reliable baseline or comparison
In managed runtimes like Java, C++, or JavaScript (V8), the just-in-time compiler dramatically changes execution characteristics after the first few hundred or thousands of invocations. Running a benchmark during the cold phase captures interpreter overhead, not the optimized machine code your production workload actually runs. Garbage collection pauses add another layer of unpredictability. A benchmark that does not account for GC cycles and JIT compilation tiers is measuring runtime infrastructure behaviour, not your code's performance.
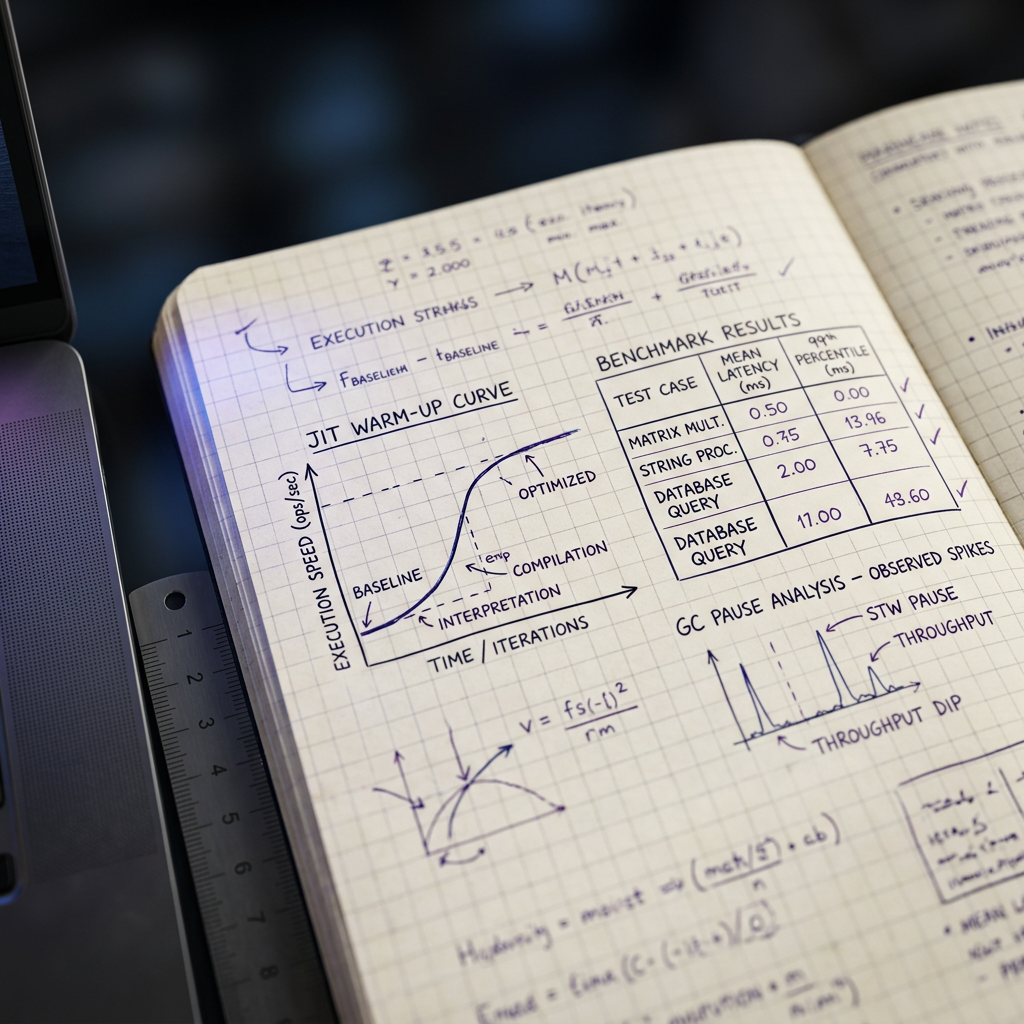
A reliable code benchmarking practice requires discipline at every stage: choosing what to measure, controlling the environment, selecting the right tools, and interpreting results without confirmation bias. The methodology matters far more than the specific framework or language.
The first question is not "how fast is it?" but "what does fast mean for this workload?" Latency percentiles (p50, p95, p99) matter more than averages for API performance benchmarking. Throughput (operations per second) matters more for batch processing. Memory allocation rate matters for GC-sensitive runtimes. Pick the metric that maps to the user-facing outcome you care about.
Environmental consistency is non-negotiable. Benchmarking on a developer laptop with Slack, Docker, and a Spotify stream running in the background produces results that are not reproducible across any other machine. Dedicated benchmark runners, whether bare-metal CI agents or isolated cloud instances with fixed CPU pinning, eliminate the system noise that makes results unreliable. At minimum, close background processes, disable CPU frequency scaling, and run on a fixed core count. Engineers who take advanced engineering habits seriously already treat environmental control as a first-class concern.
Micro benchmarking is seductive because it gives fast feedback on small code changes. But it is also the most dangerous form of benchmarking when done carelessly. Compiler optimizations can eliminate dead code paths entirely, meaning your benchmark loop might be measuring nothing literally. In Java, JMH (Java Microbenchmark Harness) exists specifically to guard against these pitfalls. In Go, the standard library's testing. B does the same. Rolling a manual for-loop with time. Now calls are almost always wrong.
The deeper trap is that micro-benchmarks rarely predict macro behaviour. A function that runs 10% faster in isolation might trigger more cache misses in a real workload, or its allocation pattern might increase GC pressure when composed with other hot paths. Always validate micro-benchmark wins with integration-level measurements before concluding anything about production impact. Teams working through technical debt decisions should weigh benchmark data at both levels before committing to a rewrite.
A solid benchmarking tools comparison for most stacks looks like this: JMH for Java, Benchmark DotNet for C++, and testing. B for Go, Criterion for Rust, and pytest-benchmark for Python. For load testing vs benchmarking at the HTTP level, tools like k6, wrk, and Locust measure system behaviour under concurrency rather than isolated function speed. These categories solve different problems, and substituting one for the other is a common mistake.
The right tool handles warm-up iterations, statistical analysis, and output formatting so you do not have to. Manually averaging three runs and calling it a result is not a benchmarking methodology. It is guessing with extra steps. Building a developer toolchain that includes purpose-built benchmarking frameworks pays dividends across every performance-related decision.
Regression testing benchmarks become valuable only when they run consistently and automatically. Treat benchmark suites like test suites: run them in CI, track results over time, and alert on statistically significant regressions. A 5% latency increase on a critical path might not matter today, but it compounds across releases. Teams practising benchmarking in agile development can attach benchmark gates to pull requests, catching performance regressions before they merge.
The key is statistical rigour. A single run tells you almost nothing. Multiple iterations with warmup phases, reported as distributions with confidence intervals, separate the signal from the noise. If your CI pipeline can run unit tests, it can run benchmarks. The question is whether your team treats performance as a first-class quality attribute or an afterthought. DevvPro has covered how observability tools like OpenTelemetry feed into this same philosophy of measurable, data-driven engineering.
Confirmation bias is the silent killer of benchmark credibility. Engineers who expect a new implementation to be faster will find ways to interpret noisy data as confirmation. Guard against this by defining success criteria before running the benchmark, not after. Decide what percentage improvement matters, what confidence level you require, and how many iterations constitute a valid sample.
Watch for outliers driven by GC pauses, thermal throttling, or OS-level scheduling. Report medians and percentiles, not means. A mean of 10ms with a p99 of 500ms tells a very different story than a mean of 12ms with a p99 of 15ms. The former has a tail latency problem hiding behind a friendly average. Developers who practice rigorous debugging already know that the first explanation is rarely the right one, and benchmark interpretation deserves the same scepticism.
Understanding these patterns is part of what separates thoughtful engineering teams from those who ship optimizations based on vibes. Resources at DevvPro consistently reinforce this principle: measure twice, ship once, and never trust a number you cannot reproduce.
Correct benchmarking is not about finding the fastest tool or writing the tightest loop. It is about understanding what you are measuring, controlling the conditions under which you measure it, and interpreting results with statistical honesty. The mistakes outlined here, from confusing profiling with benchmarking to ignoring JIT warm-up and trusting single-run results, are avoidable with discipline and the right methodology. Engineers who treat benchmarking best practices as seriously as they treat testing and code review will make better performance decisions and build systems that hold up under real-world load.
Explore more engineering deep dives and practical guides at DevvPro, The Engineering Journal.
Benchmarking in software development is the practice of measuring the performance of code, systems, or components under controlled, repeatable conditions to establish baselines and compare alternatives.
Use a purpose-built benchmarking framework for your language, run multiple iterations with warm-up phases, control your environment, and report results as statistical distributions rather than single numbers.
Choose metrics that map to user-facing outcomes, such as latency percentiles for APIs, throughput for batch jobs, or memory allocation rates for GC-sensitive applications.
Profiling identifies where time and resources are spent inside running code, while benchmarking quantifies how fast a specific operation performs under controlled, repeatable conditions.
Yes, benchmarks can and should run in CI/CD pipelines as automated regression gates that detect statistically significant performance changes before code merges into production.
.png)
.avif)